Building Recommendation Systems
Recommender systems filter information to predict how much a user would like a given item. Companies like Netflix and Tivo use these types of filtering algorithms to try to figure out what a person will want. Unfortunately, these systems are not perfect, and sometimes can go horribly wrong, as elegantly described by Patton Oswalt on the Conan O'Brien show:
Yes, bad Tivo.
So how do we improve recommender systems? Companies as well as academics are trying hard to figure this out. Fortunately, some groups released large datasets so the anyone can play with them and try to solves these issues. One such publicly available dataset is the The Million Song Dataset -- a perfect dataset for building recommender systems! So, I thought I would give it a try.
For this project, I focused on the Taste Profile subset provided by Echonest, which includes information on user play lists to build my recommenders located on my Github page. I built two recommenders; one that figures out what songs a user would like by using an input of a selected song, and another that recommends songs based on what the user has in their play list.
Both recommenders use a combination of Collaborative filtering techniques with vote counting. Collaborative filtering makes recommendations by collecting taste preferences and comparing them to other users. Here we assume that others that have the same song in their play list have similar tastes. Therefore, songs in the other users play lists would be good ones to recommend. In these recommenders I ultimately get to a list of songs that were provided by other users. I then count up how many times a song appears in other people's play lists (vote counting) and spit out the top counted songs as the top recommended songs. In this blog I briefly describe the approach for both the simple, single song recommender and the slightly more complex user recommender for users with a play list.
The Data
The Taste Profile subset contains over a million users with over 380,000 unique songs. I only use a very small subset of data that includes:
- A unique user ID
- All the songs in the user play list including:
- Song name and id
- Artist name and id
- The number of times the song was played by the user
The Simple Recommender
For my simple recommender I don't know anything about the person selecting the song. All I know is the selected artist and song. The steps for this recommender include:
- Find all users that have the song in their play list
- Make a list of all songs from each person's play list
- Count how many times a unique song appears in the list
- Print out the songs in the order of most counts that was not the original input song
Easy cheesy, right?
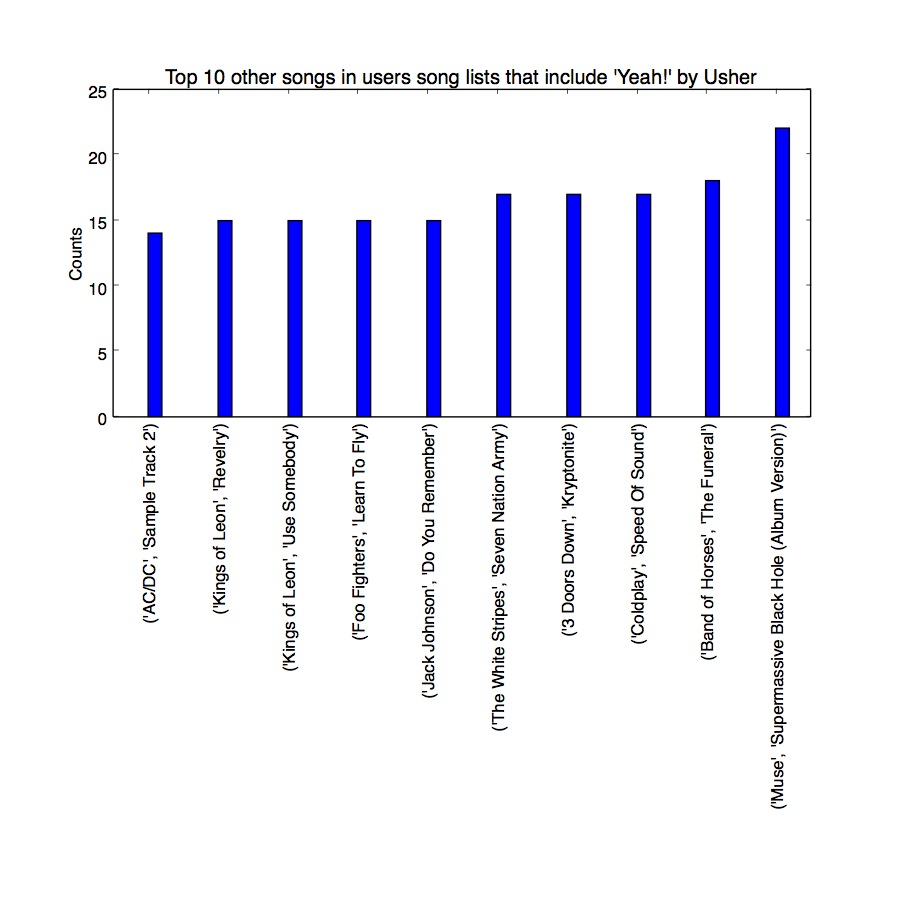
To illustrate the outcome of this recommender, here is a plot of the top 10 most counted songs from other people's play lists given the song Yeah! by Usher (keep in mind these are the counts for my much smaller subset of data):
Adding User Play List into a Recommender
Adding a user play list into a recommender is slightly more complex. Here, I want to know what other users are most similar to the recommendee (for lack of a better term, I define the recommendee as the person who is going to get the recommendation), then suggest songs from the similar users' play lists. The steps for this recommender include:
- For each song in the recommendee play list, make a list of all users that also have that song in their play list.
- Count the number of times a unique user is in the list. The user with the most counts is the most similar to the recommendee.
- Pick the most similar users and concatenate a list of songs that were not in the recommendee's play list.
- Count the number of times a song shows up in the list
- Print out the songs in order of most counted
Slightly more complicated than the simple recommender, but generally the same idea.
Pitfalls
There are issues with these simple approaches. They work well for the small data set that I downloaded, but as the dataset gets larger, the lists and dictionaries that I make in my code also get larger. So, this approach will take up increasing amounts of memory to make my lists, and increasing amounts of time to sort the lists and count the number of songs. Model-based approaches help to minimize these issues. Another issue is making recommendations based on new songs, or songs that very few people have listened to. In these cases other information about the song, such as genre, would be needed to make recommendations.
More Info on My Code
Interested in using my recommenders? Check out my Github page which includes the codes, instructions on how to use them, and some more information on how the codes work. Any comments or suggestions are welcome!
Acknowledgements
Thanks to Stella Rowlett, Jason Gowans and Manju Muthukumaresan for suggesting this project!
Comments
comments powered by Disqusblogroll
social